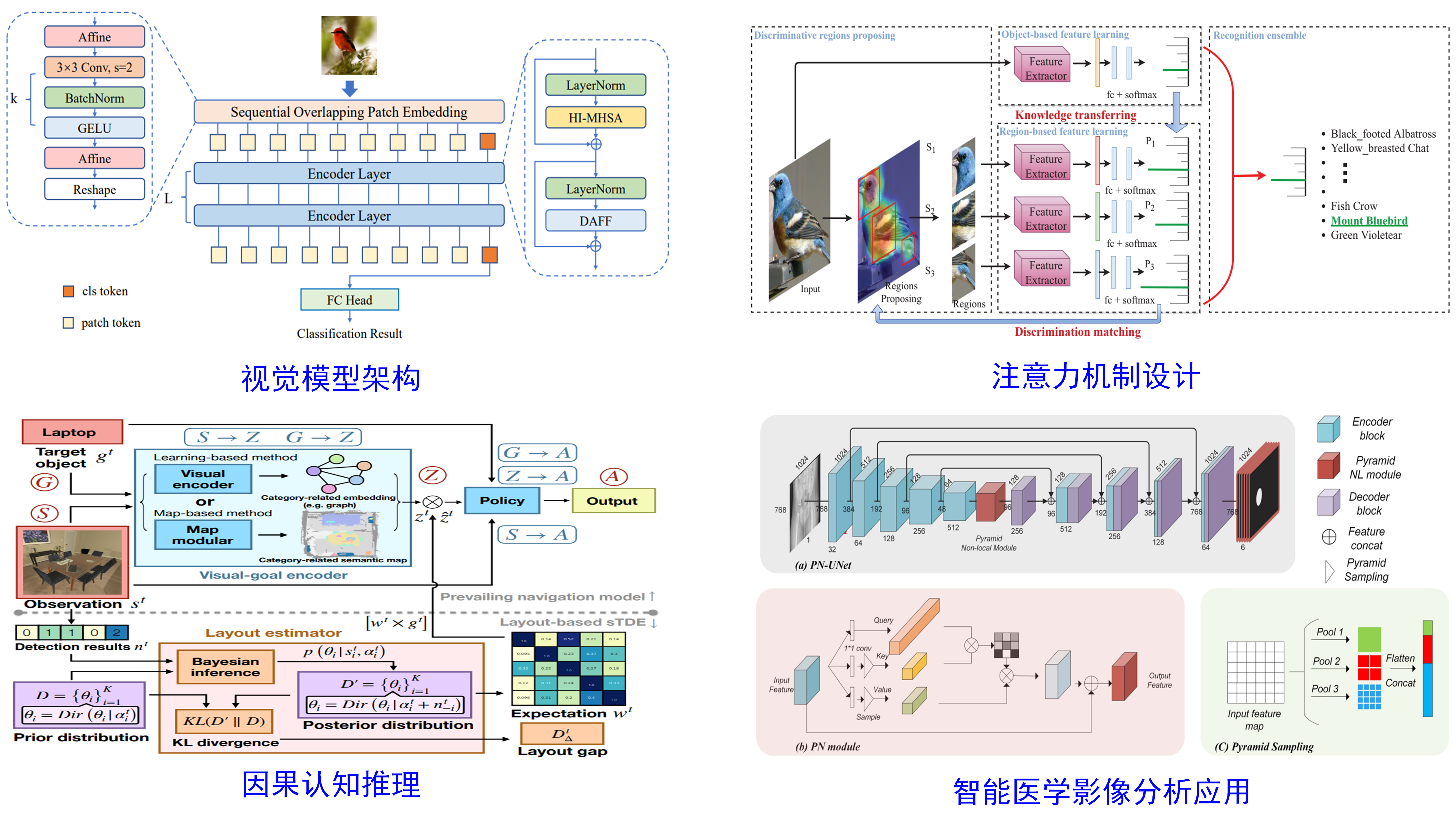
本小组研究计算机视觉的基础原理及前沿课题,主要包括:视觉模型架构,注意力机制设计,因果认知推理,医学影像应用等。视觉模型架构的研究旨在通过设计模型架构,提升深度模型的学习能力并减轻数据和资源依赖。注意力机制设计旨在模仿人类视觉过程,探索机器注意力,提升模型对信息的分辨和增强。因果认知推理目的是在大数据相关性学习之上,实现计算机视觉的因果认知学习。同时本课题组在医学影像等场景开展应用,在交叉学科任务上融入的先验知识设计深度学习范式,解决人工智能的实际应用问题。
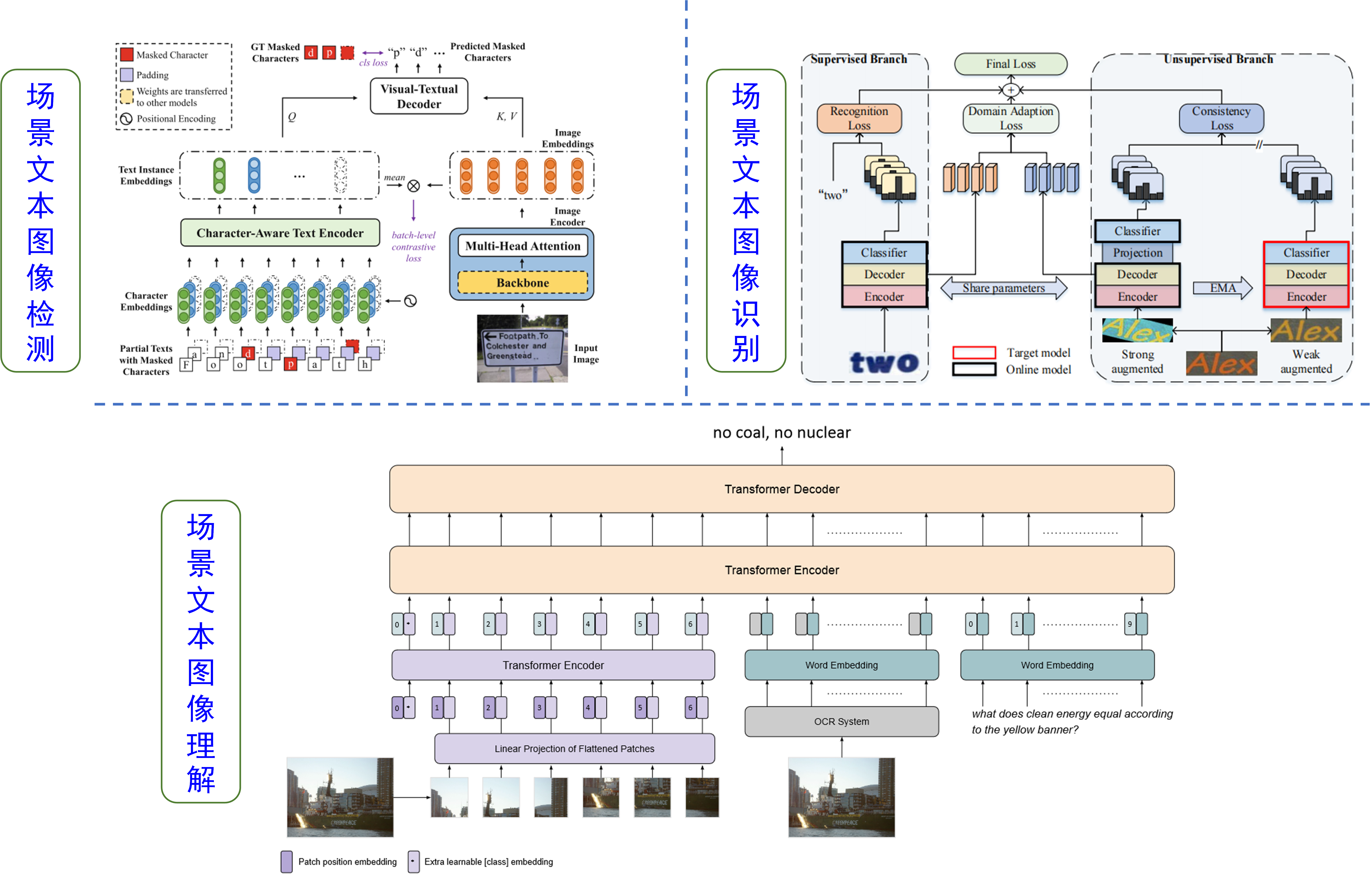
本小组主要聚焦于利用计算机视觉、自然语言处理、大模型和预训练等技术提取场景文本图像中的文本内容,并结合图像进行分析,实现对场景的深度理解。研究方向包括:文本检测、文本识别、场景文本图像理解等。文本检测和识别作为分析理解的基础,旨在将场景图像里的文本内容定位并转换为计算机可处理的字符串。场景文本图像理解任务利用文本内容、视觉特征、语言描述等跨模态信息对图像内容进行高层级、细粒度理解,如视觉问答、图文描述等。
本小组探索多模态预训练大模型的基础原理并在多个跨模态下游任务进行研究应用,研究方向包括:跨模态识别、分割、检索和生成。跨模态识别:利用文本信息构建图像和文本表征的联系,进行更有效的分类、检测等识别任务。跨模态分割:基于其它模态的描述生成描述目标像素级掩膜,其中给定描述最常见的形式为自由文本表达。跨模态分割不再局限于固定的类别,要求模型能够充分理解文本,并与图像特征实现像素级对齐。跨模态检索:以一种模态的数据作为查询来快速检索相关的其它模态数据,需要模型高效地学习模态间语义对齐。跨模态生成:基于模态之间的语义一致性,实现不同模态数据形式上的相互转换。
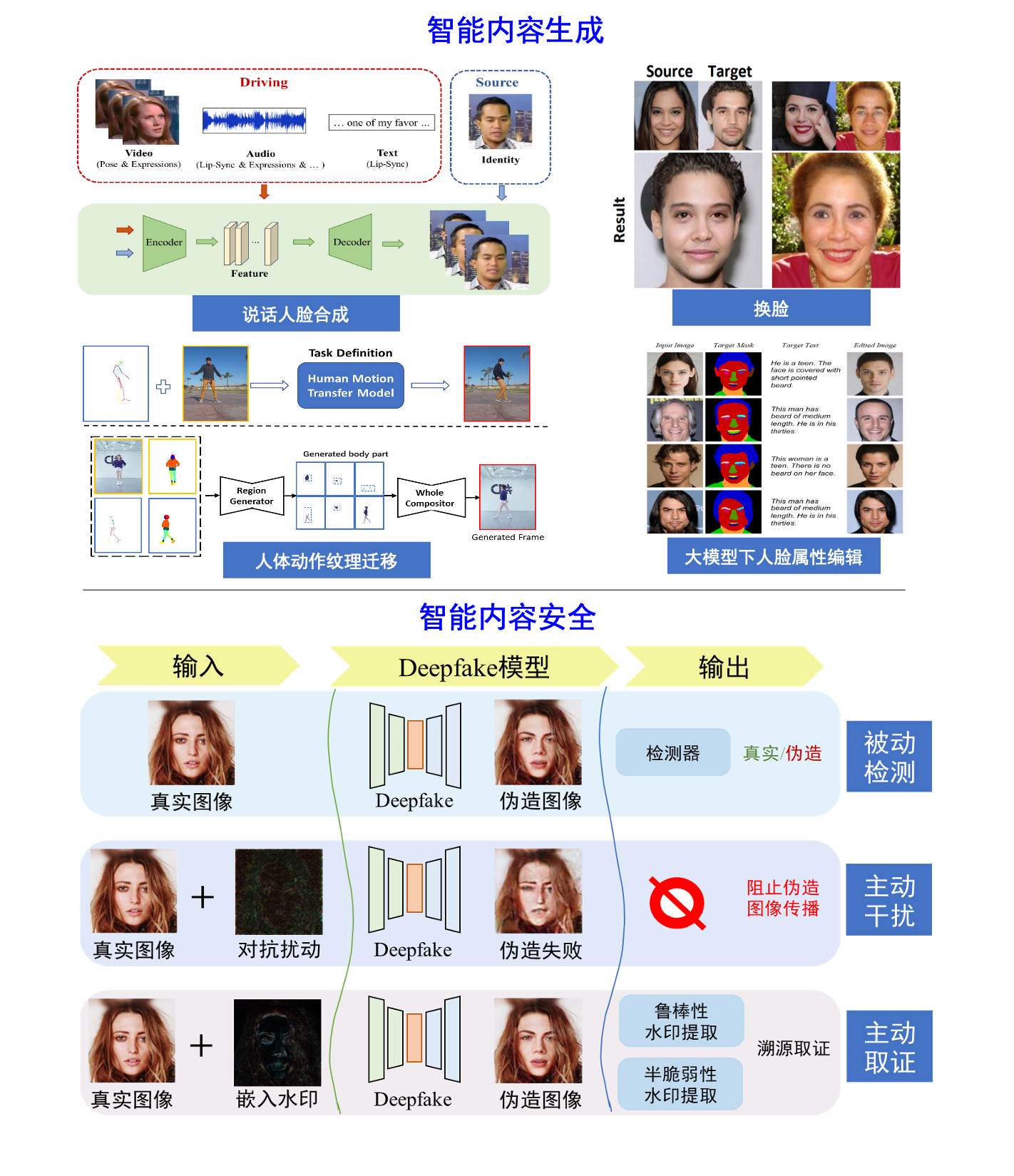
近年来,随着生成对抗网络,扩散模型以及大模型(AIGC)的兴起,视频图像内容生成技术被广泛应用于元宇宙、电影制作、影视娱乐等领域。本小组致力于人脸/人体内容生成,研究方向包括:说话人合成、AI换脸、大模型下的人脸属性编辑、人体动作和纹理迁移。说话人合成:利用给定的任意一段音频序列或文本序列,生成具有高度唇音同步属性与高自然度的人脸动画。AI换脸:致力于合成高真实感的人脸图像或视频,其中合成人脸的身份和源人脸保持一致,属性和目标人脸保持一致。大模型下的人脸属性编辑:基于大模型微调,结合多种人脸先验,实现对人脸图像的高自然度属性编辑。人体动作和纹理迁移:旨在生成特定姿态下的高保真源人体图像或视频。
此外,深度内容合成技术的滥用可能会侵犯个人隐私和财产安全,导致了虚假信息的传播,危害网络安全。因此智能内容安全的研究至关重要。本小组同时致力于人脸视频图像内容安全,研究方向包括:主动干扰、被动检测、主动取证。主动干扰:通过向人脸图像添加细微对抗噪声以实现对合成模型的干扰,进而从源头阻止虚假图像的生成和传播。被动检测:针对多种深度生成技术合成的虚假人脸,实现具有高泛化性和高鲁棒性的伪造人脸鉴别。主动取证:通过对人脸图像嵌入特定水印信息,使得人脸图像被恶意伪造后,能够根据伪造图像的水印变动实现鉴别与溯源。